In this article we are going to implement a persistent and immutable variation of the LinkedList in Java with partial structural sharing for time and space efficiency gains.
For an introduction to functional programming you can read here
Introduction
What is a LinkedList
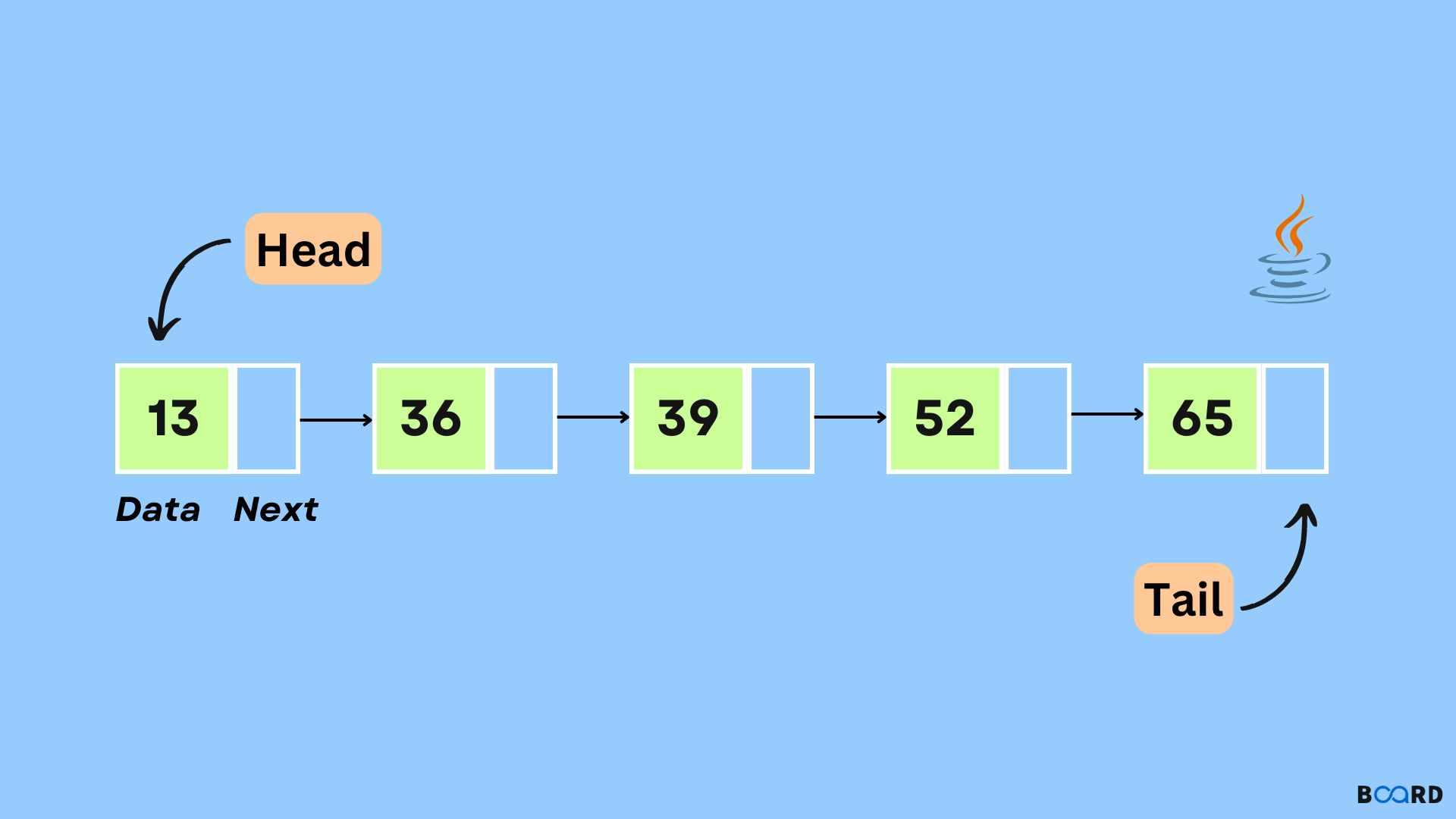
A linked list is a data structure consisting of a collection of nodes where each node contains a value and a reference to the next node in the sequence. Operations like adding an element to head of the list or removing an element from the head are O(1) operations. However, operations like adding an element to the end of the list or removing an element from the end are O(n) operations where n is the number of elements in the list.
Why do we need an immutable LinkedList
In functional programming, immutability is a key concept. Immutability means that once a data structure is created, it cannot be modified. Instead, a new data structure is created with the modifications and the original one remains unchanged.
This property allows us several benefits:
- Thread safety: Since the data structure is immutable, it can be shared across multiple threads without the need for synchronization.
- Predictability: Since the data structure is immutable, we can reason about the state of the data structure at any point in time.
- Undo: Since the data structure is immutable, we can always revert to a previous state by using the previous version of the data structure.
- Debugging: Immutability makes debugging easier since the data structure cannot be modified.
However, collections in Java and since the focus of this article is on LinkedList, are mutable by default. The reasons might be many ranging from not being an afterthought when the collections were designed to performance reasons which are inherent in immutable data structures.
Difference between Unmodifiable JDK Collections and this LinkedList
The JDK provides unmodifiable collections which are wrappers around the original collections. They support immutability but they are not persistent nor provide a true type safe way. They are wrappers around the original collections and they throw an exception when a modification operation is called. This is not the same as immutability where the data structure cannot be modified at all while ensuring that it will be difficult to get an UnsupportedOperationException at runtime.
Persistent vs Immutable
Although the terms persistent and immutable are often used interchangeably, they have different meanings. While immutability does not allow the modification of the data structure, persistence allows the sharing of the data structure when it is modified. This means that when a data structure is modified, aka a new version is created, parts of the old data structure can be shared with the new one achieving time and space efficiency gains. This technique is called structural sharing.
There are multiple ways to achieve persistence in data structures. The data structures range from simple to complex such as using balanced trees like AVL or Red-Black trees, to more complex ones like Finger trees and Radix Based Balanced Trees.
In this article, we are going to implement a simpler version of a persistent and immutable LinkedList with partial structural sharing. The reason is that LinkedList is a simple data structure and it will help us understand the concepts of immutability and persistence better and typically the implementation of more complex data structures is inherently a challenging task.
Implementation
Below we are going to implement a persistent and immutable singly LinkedList in Java using a step by step approach.
For a complete implementation and additional monads and utilities to aid with your functional programming tour to Java you can check this awesome small library FunctionalUtils.
The name we will give to our LinkedList will be SeqList and it will be a generic class.
Initially, we need to think about the operations we are going to support in our List.
- Addition to the head of the list which is going to be an O(1) operation.
- Removal of an element from the list which is going to be at worst an O(n) operation if the element is located towards the end.
- Addition to an arbitrary position in the list.
- Filtering operation to filter in / filter out elements given a predicate.
- Map and FlatMap operations to turn our List into a Monad for easier function composition.
We can think of a LinkedList as a structure consisting of nodes where each node comprises:
- head holding a value.
- tail holding the rest of the list which in turn is a LinkedList consisting of head and tail until the end of the list.
- The end of the list is represented by an empty LinkedList which means that both head and tail are null.
**The full implementation can be found in ** here
Given that the last element of the list is an empty LinkedList and each element is a node with a head and a tail, we can represent our LinkedList as a recursive data structure consisting of two classes:
public record Empty<T>() implements SeqList<T> {
}
public record Cons<T>(T head, SeqList<T> tail) implements SeqList<T> {
}
where Cons is a functional programming term named Construct dates back to the Lisp programming language.
Given the above, we can implement the SeqList interface as follows:
public sealed interface SeqList<T> permits Empty, Cons {
/**
* Creates an empty list.
*
* @param <T> the type of the elements
* @return an empty list
*/
static <T> SeqList<T> empty() {
return new Empty<>();
}
/**
* Creates a new list with the given elements. The complexity of this method is O(n) where n is
* the number of elements.
*
* @param elements the elements to add
* @param <T> the type of the elements
* @return a new list with the elements added
*/
@SafeVarargs
static <T> SeqList<T> of(T... elements) {
SeqList<T> list = empty();
for (int i = elements.length - 1; i >= 0; i--) {
list = list.add(elements[i]);
}
return list;
}
/**
* Prepends the element to the list. The complexity of this method is O(1).
*
* @param element the element to add
* @return a new list with the element prepended
*/
default SeqList<T> add(T element) {
return new Cons<>(element, this);
}
}
Let’s break down what we wrote above:
- We created a sealed interface
SeqListwhich is going to be the interface for our LinkedList. - The method
empty()creates an empty list which is an instance of the classEmpty. - The method
add()prepends an element to the list. The complexity of this method is O(1) as we are just creating a new node with the given element and the current list. This method uses Structural Sharing as the new list shares the tail of the current list. - The method
of()creates a new list with the given elements. The complexity of this method is O(n) where n is the number of elements. As it is evident we start from the last element and add it to the list. This is because we want to preserve the order of the elements.
We need to implement the remaining of our operations. Let’s start with the remove operation:
/**
* Removes the first occurrence of the element from the list. If the element is not found, the
* list is returned as is. The complexity of this method is O(n) where n is the number of
* elements. It uses structural sharing up to the element to remove. If the element is not found
* the structural sharing is not utilized.
*
* @param element the element to remove
* @return a new list with the element removed
* @throws StackOverflowError for infinite lists
*/
default SeqList<T> remove(T element) {
if (isEmpty()) {
return this;
}
if (head().equals(element)) {
return tail();
}
return new Cons<>(head(), tail().remove(element));
}
And additionally implement the tail() method and some other useful ones in our subclasses:
public record Cons<T>(T head, SeqList<T> tail) implements SeqList<T> {
@Override
public boolean isEmpty() {
return false;
}
@Override
public Optional<T> headOption() {
return Optional.ofNullable(head);
}
@Override
public Optional<T> last() {
if (tail.isEmpty()) {
return Optional.ofNullable(head);
}
return tail.last();
}
}
public record Empty<T>() implements SeqList<T> {
@Override
public boolean isEmpty() {
return true;
}
@Override
public T head() {
throw new UnsupportedOperationException("head() called on empty list");
}
@Override
public Optional<T> headOption() {
return Optional.empty();
}
@Override
public SeqList<T> tail() {
throw new UnsupportedOperationException("tail() called on empty list");
}
@Override
public Optional<T> last() {
return Optional.empty();
}
}
As we can examine from the implementation of the remove method we are using recursive calls to remove the element from
the list. This is a typical pattern in functional programming where we are using recursion to traverse the list and
remove the element. Care should be taken to avoid stack overflows in case of infinite lists. A future improvement could
be
to use tail recursion optimization which is not supported in Java but could be achieved
using trampolining.
Lastly, let’s implement the map and flatMap operations to turn our List into a Monad:
/**
* Applies a map function to the elements of the list. The complexity of this method is O(n) where
* n is the number of elements.
* <b>It does not use structural sharing</b> as it requires advanced data structures to achieve
* it.
*
* @param fn the map function
* @param <U> the type of the elements of the new list
* @return a new list with the elements mapped
* @throws StackOverflowError for infinite lists
*/
default <U> SeqList<U> map(Function<? super T, ? extends U> fn) {
if (isEmpty()) {
return empty();
}
return new Cons<>(fn.apply(head()), tail().map(fn));
}
/**
* Applies a flat map function to the elements of the list. The complexity of this method is O(n)
* where n is the number of elements.
* <b>It does not use structural sharing</b> as it requires advanced data structures to achieve
* it.
*
* @param fn the flat map function
* @param <U> the type of the elements of the new list
* @return a new list with the elements flat mapped
* @throws StackOverflowError for infinite lists
*/
default <U> SeqList<U> flatMap(Function<? super T, ? extends SeqList<U>> fn) {
if (isEmpty()) {
return empty();
}
SeqList<U> mappedHead = fn.apply(head());
SeqList<U> newTail = tail().flatMap(fn);
return concat(mappedHead, newTail);
}
/**
* Concatenates two lists. The complexity of this method is O(n) where n is the number of
* elements.
*
* @param list1 the first list
* @param list2 the second list
* @param <T> the type of the elements
* @return a new list with the elements of the two lists concatenated
* @throws StackOverflowError for infinite lists
*/
static <T> SeqList<T> concat(SeqList<T> list1, SeqList<T> list2) {
if (list1.isEmpty()) {
return list2;
}
return new Cons<>(list1.head(), concat(list1.tail(), list2));
}
As we can see from the implementation of the map and flatMap methods we are using recursive calls to traverse the
list and apply the function to each element. The flatMap method is a bit more complex as it requires the function to
return a new list which we need to concatenate with the rest of the list. Both methods are not using structural sharing
due to its
notoriety difficulty and the importance of using advanced data structures. A future improvement will be examined in a
future article.
Usage examples
Let’s see some usage examples of our SeqList.
- Imagine we have a list of integers and we want to filter out the even numbers and then multiply them in the power of two but with immutability and persistence.
SeqList<Integer> list = SeqList.of(1, 2, 3, 4, 5, 6);
SeqList<Double> updatedList = list
.filterOut(number -> number % 2 == 0)
.map(number -> Math.pow(number, 2));
- Imagine we have a list of strings and we want to concatenate them with a prefix and a suffix.
SeqList<String> list = SeqList.of("a", "b", "c", "d", "e");
SeqList<String> updatedList = list
.map(letter -> "prefix" + letter + "suffix");
- Imagine we have a list of lists and we want to flatten them.
SeqList<SeqList<Integer>> list = SeqList.of(SeqList.of(1, 2), SeqList.of(3, 4), SeqList.of(5, 6));
SeqList<Integer> updatedList = list
.flatMap(seqList -> seqList);
- Another example is pattern matching using JDK 21 switch expressions and taking advantage of the compiler checks.
SeqList<Integer> list = SeqList.of(1, 2, 3, 4, 5, 6);
switch (list) {
case Empty() -> {
// do something
}
case Cons<Integer> cons -> {
//do something else
}
}
Disadvantages
- Performance: If the list is used primarily for prepending elements of getting elements from the head of the list then the performance is good. In all other cases, O(n) is required at least with this implementation.
- Complexity: The implementation of a persistent and immutable LinkedList is more complex than its mutable counterpart.
- Memory: The implementation of a persistent and immutable LinkedList requires more memory than its mutable counterpart due to the creation of new lists for each operation. With structural sharing this is alleviated but not eliminated.
Conclusion
In this article, we implemented a persistent and immutable LinkedList in Java with partial structural sharing. We demonstrated the benefits of immutability and persistence and how we can achieve them in Java. We also showed how we can turn our LinkedList into a Monad for easier function composition. We discussed the advantages and disadvantages of persistent and immutable data structures and how they can be used in practice.





