In this article we will explain what is the token bucket algorithm, when is it used and how to implement it using Scala and making use of the library cats and specifically the IO monad.
For an introduction to functional programming you can read here
What is a token bucket algorithm?
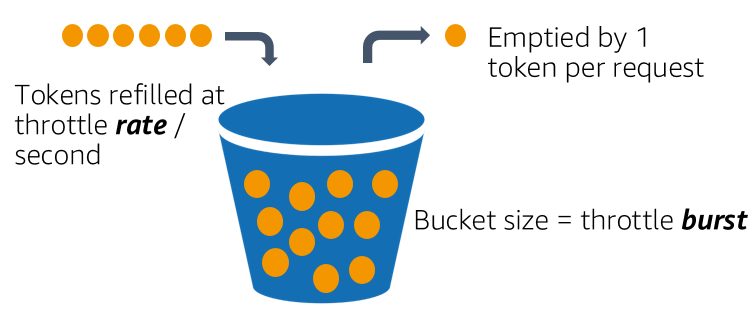
The token bucket algorithm uses a bucket containing tokens where each token is used to represent the permission to send a unit of data. The bucket is refilled constantly based on a refill rate up to a maximum specified limit. For example, if the refill rate is 10 tokens/second then a token is added to the bucket every 0.1 seconds. When a unit of data needs to be sent/processed, if there are sufficient number of tokens then the corresponding number of tokens are taken out of the bucket. Otherwise, the data is either enqueued or discarded which is an implementation detail.
What are the advantages?
- Easy to understand and implement on your preferred programming language.
- Allows a burst of activity up to the maximum capacity of the bucket.
- Prevents excessive consumption of system resources without resorting to fixed timing windows like the fixed-window rate limiting algorithm.
Where is used?
The applications can be many but the 3 most important ones are:
- Network traffic to control the flow of data to prevent network congestion.
- API rate limiting to limit the number of requests a client can make in a give time period.
- To enable multi-tenant environments to provide efficient access to shared system resources.
Steps to implement the token bucket algorithm
- Create a bucket with a maximum capacity and a refill rate.
- Refill the bucket with tokens at a constant rate.
- When a unit of data needs to be sent, check if there are enough tokens in the bucket.
- If there are enough tokens, take out the corresponding number of tokens from the bucket.
- If there are not enough tokens, either enqueue the data or discard it.
- Repeat steps 3-5 until the data is sent.
- Go back to step 2.
- Implement the token bucket algorithm in your preferred programming language.
- Test the implementation with different scenarios to ensure correctness.
Tech stack used
- Scala 2.13.14
- sbt 1.9.9
- Scalatest 3.2.18
- Cats IO 3.5.4
The following snippet is the implementation of the algorithm:
import cats.effect.{IO, Ref}
import scala.concurrent.duration.FiniteDuration
// TokenBucketRateLimiter controls the rate of some activity using a token bucket algorithm
class TokenBucketRateLimiter(
burstCapacity: Int, // Maximum tokens available at once
refillRate: Int, // Tokens added each refill interval
refillInterval: FiniteDuration // Interval between refills
) {
// Initialize available tokens to the burst capacity
private val availableTokens = Ref.unsafe[IO, Int](burstCapacity)
// Attempt to take a token
def tryTake: IO[Boolean] =
availableTokens.modify {
case currentTokens if currentTokens > 0 => (currentTokens - 1, true) // Token taken successfully
case currentTokens => (currentTokens, false) // No tokens available
}
// Start the background token refill process
def start: IO[Unit] = backgroundRefill.start.void
// Refill tokens up to the burst capacity
private def refill: IO[Unit] =
IO.sleep(refillInterval) >> availableTokens.update { currentTokens =>
math.min(burstCapacity, currentTokens + refillRate)
}
// Continuously run the refill process
private def backgroundRefill: IO[Unit] = refill.foreverM
}
// ApiKeyRateLimiter manages rate limiting for different API keys
class ApiKeyRateLimiter(
burstCapacity: Int,
refillRate: Int,
refillInterval: FiniteDuration
) {
// Alias for TokenBucketRateLimiter type
private type Limiter = TokenBucketRateLimiter
// Initialize map to hold limiters for different API keys
private val limiters = Ref.unsafe[IO, Map[String, Limiter]](Map.empty)
// Attempt to take a token for the given API key
def tryTake(apiKey: String): IO[Boolean] =
for {
limiter <- getOrCreateLimiter(apiKey)
result <- limiter.tryTake
} yield result
// Initialize and start a limiter for the given API key
def initializeLimiter(apiKey: String): IO[Unit] =
getOrCreateLimiter(apiKey).flatMap(_.start)
// Get existing limiter or create a new one for the given API key
private def getOrCreateLimiter(apiKey: String): IO[Limiter] =
limiters.modify { currentMap =>
currentMap.get(apiKey) match {
case Some(limiter) => (currentMap, limiter) // Return existing limiter
case None =>
val newLimiter = new TokenBucketRateLimiter(burstCapacity, refillRate, refillInterval)
(currentMap.updated(apiKey, newLimiter), newLimiter) // Create and return new limiter
}
}
}
With employing the Ref we can ensure that our code is free from race conditions and being thread safe.
Below is the snippet of testing the implementation with a unit test:
import cats.effect.IO
import cats.effect.testing.scalatest.AsyncIOSpec
import cats.implicits._
import org.scalatest.Assertion
import org.scalatest.freespec.AsyncFreeSpec
import org.scalatest.matchers.should.Matchers
import scala.concurrent.duration._
class ApiKeyRateLimiterTest extends AsyncFreeSpec with AsyncIOSpec with Matchers {
val burstCapacity: Int = 5
val refillRate: Int = 5
val refillInterval: FiniteDuration = 500.millis
val rateLimiter = new ApiKeyRateLimiter(burstCapacity, refillRate, refillInterval)
"ApiKeyRateLimiter should" - {
"handle requests independently for each API key ensuring token bucket uniqueness" in {
testApiKeyIndependence("key1", "key2")
}
"allow additional requests after refill interval" in {
testRefillInterval("key3")
}
}
def testApiKeyIndependence(apiKey1: String, apiKey2: String): IO[Assertion] =
for {
_ <- rateLimiter.initializeLimiter(apiKey1)
_ <- rateLimiter.initializeLimiter(apiKey2)
results1 <- List.fill(burstCapacity)(apiKey1).traverse(rateLimiter.tryTake)
results2 <- List.fill(burstCapacity)(apiKey2).traverse(rateLimiter.tryTake)
extraTry1 <- rateLimiter.tryTake(apiKey1)
extraTry2 <- rateLimiter.tryTake(apiKey2)
} yield {
assert(results1.forall(_ == true))
assert(results2.forall(_ == true))
extraTry1 shouldBe false
extraTry2 shouldBe false
}
def testRefillInterval(apiKey: String): IO[Assertion] =
for {
_ <- rateLimiter.initializeLimiter(apiKey)
_ <- List.fill(burstCapacity)(apiKey).traverse(rateLimiter.tryTake)
_ <- IO.sleep(refillInterval * 2)
result <- rateLimiter.tryTake(apiKey)
} yield result shouldBe true
}
Why the usage of IO Monad
The implementation of the algorithm contains impure functions
since it produces side effects such as thread sleeping and updating the Ref state. By using IO monad we encapsulate those side effects
in a monad so as we can code with pure functions.
The advantages of IO are:
- Encapsulated side effects in a purely functional way.
- Allows for asynchronous and concurrent execution. The
refillmethod uses IO.sleep to pause for a given duration without blocking the underlying thread, allowing other tasks to run concurrently. - Composition. We can use multiple
mapandflatMapoperations to compose effectful operations together in a readable manner. - Resource safety. Using IO we can ensure that the underlying threads will be released once they are finished.
An example of how IO can encapsulate the effects of an impure function in a purely functional way:
def tryTake: IO[Boolean] =
availableTokens.modify {
case currentTokens if currentTokens > 0 => (currentTokens - 1, true)
case currentTokens => (currentTokens, false)
}
This method creates a side effect which is to modify the state of the Ref. By wrapping it in IO we encapsulate the effect in a purely
functional way and defer the execution of the side effect until the end (usually when the actual thread starts).
This is a powerful concept because we can reason about our code more easily.